
ANALYSING TEXT IN LANGUAGES OTHER THAN ENGLISH
Leximancer can process text in languages other than English. The languages currently supported in the software are listed in the sidebar.
Default Language Support
English Danish German Finnish Greek Spanish French Croatian Indonesian Italian Malay Dutch Polish Portuguese Russian Serbian Swedish Turkish
SUPPORTING NEW LANGUAGES
It may be possible to support new languages in Leximancer if there are clear markers for word and sentence breaks. A 'stop-list' of frequently used terms (for example 'and', 'the', 'but' etc.) must be compiled in the desired language so that these words can be excluded from processing as concept candidates.
Note: Leximancer supports processing of text that is a single language per document or file at this stage (this includes CSV files that often represent multiple documents, with a 'document' being a text column cell).
CAN YOU MODEL MULTIPLE LANGUAGES IN THE SAME LEXIMANCER ANALYSIS/MAP?
Yes, but the results may not be immediately what you wanted. Leximancer does not perform automatic translation, so two concepts from different languages which mean the same thing are not automatically merged using normal text data. The resulting map would have largely separate concept clusters for each of the languages. You can merge hub concepts manually across languages, and if you merge enough, the language clusters will merge.
To map data from more than one language in the same project, you must do two things:
specify the language for each data set when they are selected for the project; and
you must load a stoplist in the stoplist editor (using the ‘Load language’ button at the top) for each of the additional languages.
WHY ARE STOP-WORDS FOR NON-ENGLISH LANGUAGE DOCUMENTS STILL PRESENT IN A PROJECT?
To automatically add the stop-list for a document language, the language should be selected in the dropdown language list when a source text document is added to a project, before any other steps in the project have been run.
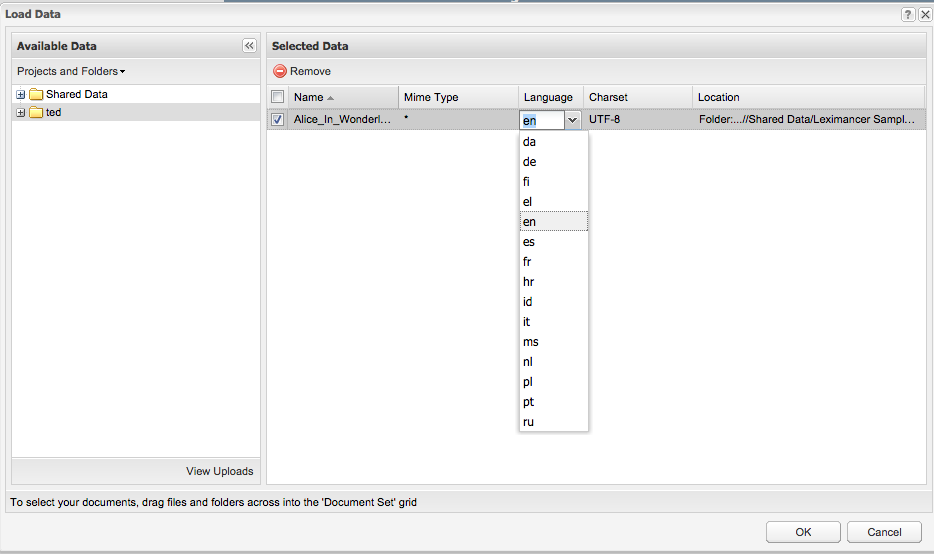
Selecting a language for a text document in Leximancer
If the language is not selected before the project is run, Leximancer sets a default set of stop-words which is usually for English. No further automatic changes are made to the stop-word list.
To add a new language or update specific stop-list terms after a project has run any steps, the stop-list editor dialogue should be used. This dialogue is available from the Text Processing Settings dialogue by pressing the Edit stoplist button. New stop-list languages may be added from there.

Editing a Leximancer project stop-list.
CROSS-LINGUAL CONCEPTS
There is a special form of data which will cause cross-lingual concepts to be discovered automatically, which can be very interesting. The data required is called an interlinear translation - each sentence in one language has the translation of that sentence into another language immediately after it. To process this sort of data, you need to create a special multi-language stoplist where all the stop words share the same literal language code in the list.
DO I NEED A SPECIAL VERSION TO SUPPORT ANOTHER LANGUAGE?
Leximancer has support for multiple languages built-in.
HOW DO I SELECT THE LANGUAGE FOR A DOCUMENT?
You must select the language code for each data file when you drag it into the text selection panel. If you hover the mouse over the codes in the list, you can see the full name of each language. You may need to change the Charset (character encoding) from the default utf-8. This character encoding is an attribute of your data.
WHAT SPECIAL CONSIDERATIONS ARE THERE FOR LANGUAGE DIFFERENCES?
There are several considerations for using languages other than English. These are summarized below.
Stop Word Removal
Selecting the language when you drag across each data file or folder will activate a stop list for those languages. You may also need to change the Charset (character encoding) setting next to the language setting for some data sets. Character encoding is an attribute of your data.
Upper Case Words
In Leximancer, Name-like concepts are identified using upper case. In Leximancer maps and analysis, name-like concepts are not treated very differently from word-like concepts. However, this may be undesirable in some languages (e.g., German) due to the capitalization of all nouns. If you wish to disable the identification of proper names, there is a pre-processor stage setting to allow this. It is called: Identify Name-like Concepts. Deselect this option.
Stemming
Leximancer also includes optional language stemmers for many languages. Just enable Merge Word Variants in the Preprocessor.
HOW DO I EDIT THE STOP WORD LIST FOR A SUPPORTED LANGUAGE?
You can edit the stop word list in the settings for the Pre-Process stage of project control. There are most likely other stop words you will want to add to our default list. After saving the edited stop word list, you can open it again and use the download button to save your modified stop list to your local disk. You can upload this to other projects using the Upload button in the stop word editor.
WHAT LANGUAGES ARE SUPPORTED?
The current list of supported languages can be found above. Languages that do not have readily identifiable word spacing cannot be used with Leximancer at this time (e.g., Mandarin).
There is a workaround for this situation. If you were to manually insert word breaks into Mandarin text it would be possible to upload your own stop list into a project if desired. Again, this is not something we provide support for at this time.
WHAT CHARACTER SETS ARE SUPPORTED?
ISO-8859-1, ISO Latin Alphabet No. 1,
US-ASCII, American Standard Code for Information Exchange,
UTF-8, Eight-bit UCS Transformation Format,
WINDOWS-1252, Windows Western Alphabet,
MacRoman, Apple Standard Roman,
UTF-16, Sixteen-bit UCS Transformation Format, byte order identified by an optional byte-order mark,
UTF-16BE,Sixteen-bit UCS Transformation Format, big-endian byte order,
UTF-16LE,Sixteen-bit UCS Transformation Format, little-endian byte order,
WINDOWS-1250, Windows Eastern European,
WINDOWS-1251, Windows Cryillic,
WINDOWS-1253, Windows Greek,
WINDOWS-1254, Windows Turkish,
WINDOWS-1257, Windows Baltic,
ISO-8859-2,ISO Latin Alphabet No. 2,
ISO-8859-4,ISO Latin Alphabet No. 4,
ISO-8859-5,Latin/Cyrillic Alphabet,
ISO-8859-7,Latin/Greek Alphabet,
ISO-8859-9,ISO Latin Alphabet No. 5,
ISO-8859-13,ISO Latin Alphabet No. 7,
ISO-8859-15,ISO Latin Alphabet No. 9,
KOI-R, KOI8-R Russian
KOI8-R, KOI8-R Russian